Monday Morning Takeaway
The brands with the most defensible budget decisions are not choosing between MMM and incrementality testing. They are running both in a closed loop, recalibrating every Monday instead of every quarter.
The Stakes: Why the False Choice Has a Price Tag
Three out of four marketers say their measurement approaches, including attribution, incrementality, and MMM, are not delivering the speed, accuracy, or trust they need, according to the IAB and BWG Global’s State of Data 2026 report. Nearly half (46.9%) of US marketers plan to invest more in MMM over the next year, yet the decision on whether to test MMM vs. incrementality is being made before measurement maturity has caught up with the investment.
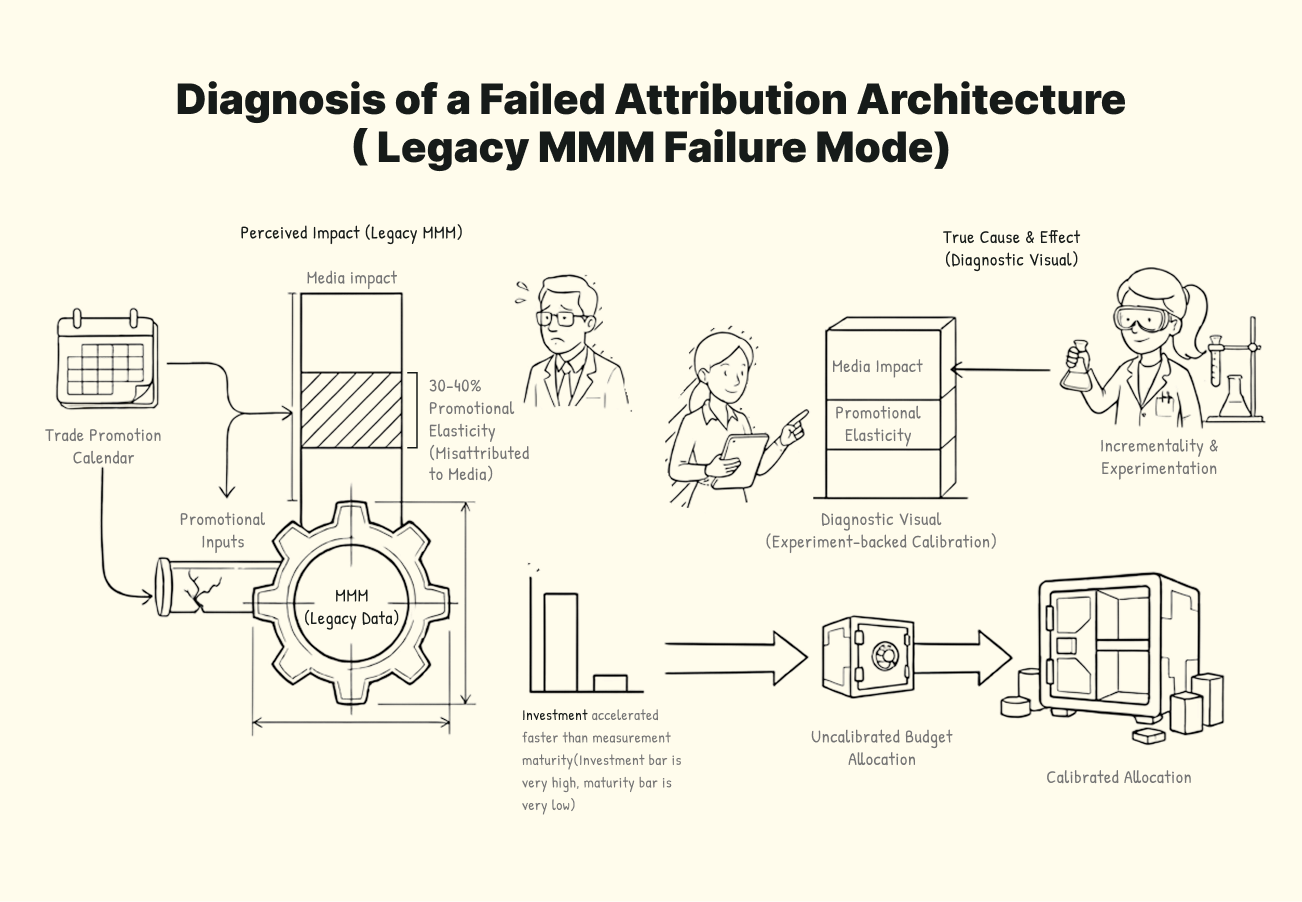
Industry research estimates up to 60% of digital marketing spend is wasted due to misattribution. The specific failure mode is this: brands using trade promotion calendars in their MMM routinely find that 30–40% of perceived media impact is actually promotional elasticity, a finding consistent across CPG category research and validated by LiftLab client analysis. The model credits the media campaign, even though the price reduction did most of the work. The problem is not with the platform or the talent. It is with the incrementality testing solution, operating at a scale most brands do not realize until the budget has already moved in the wrong direction.
Privacy-driven tracking loss, walled garden measurement limitations, and the collapse of third-party cookie infrastructure have made this structural gap impossible to ignore. The gap between the problem and the ability to see it is as structural as the problem itself.
The fix isn’t switching methods. The MMM vs. incrementality testing debate has the wrong frame entirely. It’s running them together in a way that makes each one more accurate than it would be on its own. Every week that the budget runs on an uncalibrated model is a week the misallocation compounds, over crediting the channels that capture demand and starving the ones that create it.
How MMM and Incrementality Testing Actually Work, and Why They Disagree
When MMM and an incrementality test return different numbers, that gap is not a problem to debug. It is built into how each method works. MMM reads patterns in historical data. Incrementality testing runs a controlled experiment to prove cause. They are asking different questions, so they will always land differently. That difference is the most useful thing either method produces. It tells you exactly where the model is working from an assumption rather than evidence.
What MMM Measures and What It Cannot
MMM captures what no other tool can: paid social, offline channels without clickstream data, and brand effects that take months to surface. But as an observational model, it can only establish correlation, not causation. LiftLab analysis shows that observational models systematically overestimate credit channels that capture existing demand rather than create it.
The root problem is self-selection bias: when the performance marketer spends $2 million on Meta and generates $2.5 million in revenue, the model credits the advertising. But what if the customer was already looking?
An MMM is only as unbiased as the spend history it trains on. If budgets have been allocated for years based on last-click attribution, the historical data reflects those decisions, and the model learns from a spend distribution that was already skewed toward channels that captured demand rather than created it.
MMM also measures activation only. Brand equity investment that lifts baseline demand over 6 to 52 weeks is structurally invisible. The scale of that invisibility has been quantified: a landmark field experiment published in the INFORMS Journal of Marketing Science, involving over 3 million users and a national apparel retailer, found that 84% of the total sales increase attributable to online advertising came from offline sales, invisible to any measurement system that only tracks digital outcomes.
What Incrementality Testing Proves and Where It Stops
Incrementality testing fills the causation gap that MMM cannot close. By splitting audiences into treatment and control groups and measuring true causal lift, it isolates what the advertising actually caused rather than what it correlated with. It fills the causation gap. But it answers one question per channel, one at a time. It cannot tell you how the answer changes when you scale YouTube or cut TV. Only MMM aggregates across the portfolio.
Incrementality testing is the gold standard for proving what happened in a single window. That precision is also exactly what makes the aggregation problem so costly; the more accurate the individual test, the more painful it is that the result exists in isolation.
Forecasting is limited: results reflect only the conditions of a specific test.
Why the Disagreement Between Them Is Built-In
MMM estimates contribution by finding correlations in historical spend and sales data across all channels simultaneously. Incrementality testing isolates the effect of one channel by holding everything else constant. One is observational and broad. The other is experimental and narrow. They will produce different numbers by design, and that is expected. It is a signal identifying exactly where the model relies on correlation in a region where that correlation is unreliable.
This is exactly what LiftLab’s Trust Engine uses to generate its experimentation roadmap.
This is the core of the incrementality-testing vs. MMM closed-loop debate. It is not about choosing between methods but focusing on the signal between them.
The Trust Engine is LiftLab’s closed-loop recalibration mechanism. It constrains MMM coefficient estimates to experimentally verified ranges using Bayesian priors and runs on a weekly cadence rather than quarterly. It is not a reporting layer. It is the mechanism that makes each method more accurate because of the other.
What Goes Wrong When You Rely on One Method Alone
What are the limitations of using MMM alone?
Self-Selection Bias: Platform attribution hands MMM a distorted picture before the model even runs. An MMM trained on last-click data learns last-click assumptions. The result: last-click reporting overvalues branded search by around 21% relative to its true incremental contribution, a finding from comparative attribution model research, and an uncalibrated MMM absorbs that distortion as fact. The budget follows the model, shifting toward retargeting channels that harvest demand rather than create it. Brand spend shrinks. So does the baseline demand that made retargeting look efficient in the first place.
Trade Promotion Conflation: When a trade promotion and a media campaign run at the same time, the MMM must decide which one moved the needle. It usually picks the media campaign because that is where the spend variation is clearest, and attribution is easier to claim. In CPG, research shows that 30–40% of what gets credited to media is due to promotional elasticity. The price drop did the work. The campaign got the credit. An estimated $500 billion is spent on CPG trade promotions annually, and between 35–40% of that spend is considered wasted, partly because no measurement system cleanly connects trade and media effects, according to CPG industry analysis.
The Monday Problem – Quarterly MMM Refresh Cycles Break Budget Decisions
A traditional MMM refreshes quarterly. By the time Monday’s budget call happens, the model is running on outputs that are up to 90 days old. CPMs have shifted. Creative has fatigued. Auction dynamics have changed. None of that is visible in a model that was last updated three months ago. Every budget decision made between refreshes is being made against a market that no longer exists.
Last-click models overvalue remarketing campaigns by 19–27% during promotional periods alone. Running budget decisions on an MMM platform compounds that distortion with every passing week. At LiftLab, our innovation PlatformSense addresses this directly by applying daily effectiveness modifiers to stable long-run response curves, so the model never runs on 90-day-old coefficients.
What are the limitations of using incrementality testing alone?
The Aggregation Problem: A single geo holdout test answers one question about one channel at one spend level. It cannot tell you what happens to that answer when YouTube scales, or TV cuts, or a competitor increases share of voice. The results exist in isolation. Only MMM holds the full portfolio view and can model how channels interact. A LiftLab client in multi-brand retail closed this gap by running MMM calibrated with incrementality experiments, reallocated $8M based on the combined output, and grew total revenue by $22M the following year.
Speed and Coverage: A single geo experiment consumes 4–8 weeks of clean pre-period data, 4–6 weeks of treatment, and 2–3 weeks of washout. Run the numbers across a full channel portfolio, and you are looking at more than a year of continuous testing to cover the major channels once. Most brands run 8–10 tests per year, covering four or five channels at best. The other channels in your media plan are running on historical correlations, and without a model telling you which carries the most measurement risk right now, the test budget goes to whoever asked the loudest, not to where the decision risk is highest.
No Forecasting: Incrementality testing tells you what happened. When your CFO asks, “What happens if we move $2M from Meta to CTV next quarter?”, incrementality testing has no answer. That question requires a model with response curves capable of simulating outcomes at spend levels you have never tested.
MMM vs. Incrementality Testing: Side-by-Side Comparison
| Comparison Parameters | MMM | Incrementality Testing |
|---|---|---|
| Method Type | Correlational contribution of each channel across the full portfolio. | True causal lift for one channel in one specific time window. |
| Primary Strength | Breadth: sees all channels simultaneously, captures long-lag brand effects, and enables forecasting. | Precision: eliminates confounding, isolates what the advertising actually caused. |
| Primary Limitation | Correlation is not causation; quarterly lag; no saturation ceiling; self-selection bias. | Narrow scope; too slow to test everything; cannot produce a portfolio view; no forecasting. |
| Refresh Cadence | Quarterly or annual. | Per experiment, typically 4–6 weeks per test. |
| How the Closed Loop Addresses This | Trust Engine constrains MMM coefficients via Bayesian priors from geo experiments. PlatformSense applies daily modifiers, so the model never runs stale. The Monday Workflow delivers a fresh reallocation brief every week. | The Trust Engine uses the MMM’s wide confidence intervals to prioritize the experimentation roadmap. Highest-uncertainty channels get tested first. Results return as causal anchors that recalibrate the model’s response curves. |
Seeing the gap between your MMM and incrementality results, but unsure where to act? Talk to a LiftLab measurement strategist about where to run your first experiment.
The Integration Architecture: How the Closed Loop Works in Practice
Step 1: MMM Identifies Where Uncertainty Is Highest
The first step in running MMM and incrementality testing as a closed loop is letting the model tell you where to experiment. Some channels carry more uncertainty than others. The ones most prone to it are those where spend moves in sync with seasonality, trade promotions, or competitor activity, because the model cannot isolate the advertising effect cleanly from those concurrent signals. The MMM makes this visible through wide confidence intervals. A wide interval is not a weakness in the model. It flags where to experiment next.
IMPORTANT – Wide confidence intervals = the next experiment destination.
Step 2: Experiment Results Become Causal Anchors
An MMM estimated Paid Social at $1.20 in revenue per dollar spent. A geo holdout experiment returned a true incremental causal lift of $0.85. The Trust Engine constrained the model’s Paid Social coefficient to a range anchored at the experimental result. The next budget recommendation was based on causal evidence, not a correlation that had been overestimated by 41%. The capital that had been scaling into that overestimation was reallocated to channels the closed loop had identified as undersaturated.
Once complete, the result is fed back into the model to recalibrate estimates, directly changing budget allocation decisions from correlation-based guesswork to causal evidence. Over time, this reduces structural bias. Over-credited channels (usually lower-funnel or easily trackable media) lose excess attribution. Under-credited channels (often upper-funnel or offline) begin to reflect their true contribution in the response curves that govern every scenario the model produces.
The outcome was defensible only because the budget allocation solution had been anchored in causal evidence, not in correlation alone. had been anchored to causal evidence, not correlation alone.
The Monday Workflow: What Recalibration Looks Like in Practice
The Monday Workflow runs on three nested cadences:
| Timeframe | Activity | Output | Decision Owner |
|---|---|---|---|
| Weekly | PlatformSense modifier update; mROAS scores refresh; uncertainty flags reviewed. | Channel-level reallocation brief. | VP Performance / Growth |
| Weekly | MMM surfaces highest-uncertainty channels; experimentation roadmap updated. | Next geo-test prioritization. | Marketing Science Lead |
| Monthly | Experimental results reviewed; Bayesian priors updated in MMM. | Calibrated response curves: scenario planner inputs refreshed. | CMO / Marketing Science |
| Quarterly | Full scenario planning cycle; CFO-ready forecast ranges; brand equity review. | Approved budget allocation for the next period. | CMO + CFO joint |
What Changes After the Loop Is Running
Success Story: From Hypothesis to Board-Ready Proof (SKIMS)
Before:
The SKIMS team had identified TikTok as a high-potential channel for a specific demographic. The hypothesis was sound. What they lacked was causal proof to justify a significant investment over platform-reported attribution.
What LiftLab ran:
LiftLab designed geo-based experiments on TikTok Ads through the Trust Engine, as shown in the SKIMS success story, exposing specific regions to SKIMS ads on TikTok while holding out others, isolating true causal lift from baseline demand. PlatformSense flagged the divergence between platform-reported signals and actual auction dynamics, giving the team the evidence it needed to stop trusting the dashboard and start trusting the experiment.
After (What was achieved):
Tripled Ad spend efficiency
2.9% daily revenue increase
1.7% profit boost
The closed loop also made brand equity visible, LiftLab’s Long-Term Impact modeling captured the 6–52 week carryover effect on baseline demand, giving the CMO a P&L line for brand investment that a quarterly MMM would never have surfaced.
The Measurement Architecture Your CFO Can Actually Defend
Nielsen research shows 85% of marketers say they can measure holistic ROI. Only 32% actually do. That 53-point confidence gap is not closed by better data or more sophisticated tools alone. It is closed by a system in which models and experiments constrain each other, where every correlation is continuously corrected by causation, and where the marketing measurement gap between what brands think they know and what they can prove is systematically reduced with every experiment that runs.
Every budget decision in the closed loop traces back to a named experiment with a published confidence interval. Not a modeled average. Not a directional estimate. A causal measurement with an explicit uncertainty range that any stakeholder can examine and challenge.
When your VP of Performance Marketing walks into a CFO meeting with a budget recommendation built on the closed loop, the question shifts from “which number is right” to “how confident are we in this decision, and what would change that confidence?” That is a conversation the CFO can participate in. That is a conversation that gets the budget approved.
Gartner research finds that fragmented, siloed data costs enterprises $12.9 million annually in missed opportunities and wasted investment. Marketing budgets fell 15% in a single year in 2023–24, primarily because marketing could not prove ROI to Finance. The measurement gap is a budget problem with career consequences.
Want to plan your next budget move with confidence backed by causal evidence? Book a LiftLab Demo here.
Frequently Asked Questions
What is the difference between MMM and incrementality testing?
MMM measures historical correlation across all channels to estimate channel contributions and enable forecasting. Incrementality testing proves causation for one channel at a time through controlled experiments by splitting audiences into treatment and control groups, but it cannot provide a portfolio view. Neither method alone closes the full measurement gap. MMM looks back across the full portfolio over months or years; incrementality testing isolates a single channel within a window of days or weeks. If MMM estimates high and an experiment returns low, the Trust Engine uses that divergence to decide which channel to prioritize next.
Can you use incrementality tests to calibrate a media mix model?
Yes, and this is the most reliable way to calibrate a marketing mix model. Experimental results enter the Trust Engine as Bayesian priors, constraining model coefficients to the ranges of causal evidence. Every experiment is evaluated against channel-specific design requirements before being entered into the model. Low-quality experiments do not produce weak calibration. They produce incorrect calibration, degrading the MMM accuracy more than no calibration.
What happens when MMM and incrementality test results disagree?
The disagreement is a routing signal, not an error. It identifies regions where the model relies on an unreliable correlation. The wider the divergence, the higher that channel ranks on the Trust Engine’s experimentation roadmap. Once a new experiment recalibrates the coefficient, the disagreement that triggered it is what makes the closed loop more accurate over time.
Which geo-test method should you use for each channel?
The method is determined by channel mechanics, not convenience. Geo holdout works for offline channels where geographic containment is clean. Synthetic control suits always-on digital channels, requiring 8 to 12 weeks of pre-period data. User-level lift applies to walled-garden platforms but requires independent validation before it can enter the Trust Engine as a Bayesian prior. The wrong method produces a contaminated causal anchor that degrades the model to below-observational-inference performance.
How does experiment quality affect MMM calibration?
Experiment quality is not a calibration input. It is a gate. The Trust Engine evaluates every experiment against channel-specific design requirements before it enters the model. A low-quality experiment produces a wrong causal anchor, not a weak one, degrading MMM accuracy. The Trust Engine selects test methods by channel mechanics, not convenience. That is what separates a system that improves with every experiment from one that compounds its own errors.
How often should a marketing mix model be updated?
With the right architecture, the model is never stale. The Monday Workflow runs three nested cadences. Weekly: PlatformSense applies daily effectiveness modifiers, so decisions never run on 90-day-old coefficients. Monthly: Bayesian priors update as experimental results recalibrate model coefficients. Quarterly: a full scenario cycle produces CFO-ready forecast ranges. The architecture separates what changes daily, monthly, and quarterly, so the model stays continuously current.
Is MMM or incrementality testing better for budget planning?
Neither method plans the budget alone. MMM provides the portfolio view, response curves, and forward-looking scenarios. Incrementality testing provides causal proof for one channel at a time. A budget built on MMM alone is correlation dressed as conviction. A budget built on incrementality alone is a point-in-time proof with no portfolio context. Running both in a closed loop, where experiments constrain the model and the model prioritizes the experiments, is the only approach a CFO can audit from assumption to allocation.